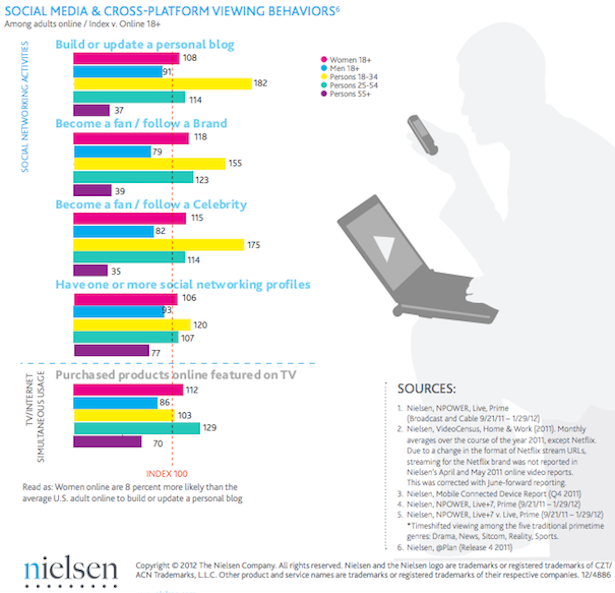
Kilkenny Castle
My Smithsonian internship is still going well as I research cultural and heritage sites in Ireland. I have completed 60% of the coding for these sites and will soon be turning my attention to mapping.
Researching the significance of Kilkenny Castle was both challenging and enjoying. Kilkenny Castle has a complex history that involves architecture, politics, history, archaeology, culture, and various military functions. At present, it also serves as an important site for public audiences across multiple disciplines on local, national, and international levels.
This site was part of my research for the Conflict Cultures project, which connected me to the Smithsonian and the University of Pennsylvania as a digital historian and digital humanist. For example, only a handful of entries involve both a prior military function and a current relationship to the state. For these categories I coded them both as “1” that designates it as a site that could be potentially endangered if Ireland ever experiences either a national or man-made disaster (civil war, terrorist attack, hostile occupation). In other words, coding and mapping this site will help future generations protect, preserve, and learn about the important role of Kilkenny Castle in Ireland’s history. While I have never used Google Fusion Tables as platform for GIS mapping, this entry (along with 318 others) taps into the mapping skills gained through my digital public humanities coursework through George Mason University.
 Normek82, Kilkenny Castle, 2015 (Wikimedia Commons, CC 4.0).
Normek82, Kilkenny Castle, 2015 (Wikimedia Commons, CC 4.0).

It primarily features medieval and baroque architecture. In addition to serving as a residence, the castle also served as a fortress. The buildings have been in the care of the Office of Public Works since 1969. Visits to the Kilkenny Castle feature several types of collections: decorative arts, art, textiles, print materials, military artifacts, and archaeological artifacts. The mission of the Kilkenny Castle and the Office of Public Works includes archaeological excavation, conservation, preservation, and restoration of the buildings as well as the collections.
Sources and Further Reading:
Bence-Jones, Mark. A Guide to Irish Country Houses (London: Constable Press, 1998).
Bron, Daniel. Kilkenny Castle and Fountain, 2013 (Wikimedia Commons, CC 3.0).
Department of the Environment. An Introduction to the Architectural Heritage of County Kilkenny (Government of Ireland, 2006).
Murtagh. Ben. “The Kilkenny Castle Archaeological Project 1990 to 1993,” Old Kilkenny Review (Kilkenny Archaeological Society, 1993).
Normek82, Kilkenny Castle, 2015 (Wikimedia Commons, CC 4.0).
Office of Public Works, “An Introduction to Kilkenny Castle,” Kilkenny Castle (Government of Ireland, 2017).
Williams, Jeremy. A Companion Guide to Architecture in Ireland 1837– 1921 (Dublin: Irish Academic Press, 1994).

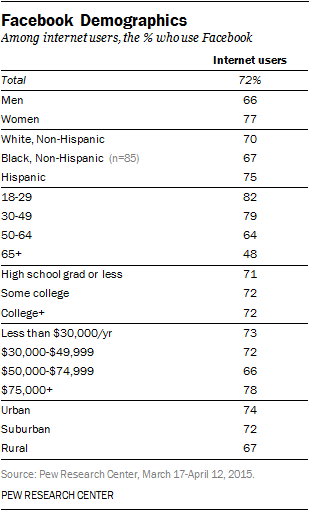




{kind=link}
{kind=link}