American Consumer Culture homepage
*Copyright information bottom of post
One of the most engaging, comprehensive, and unique databases I have recently discovered is called American Consumer Culture: Market Research and American Business. This database provides insight into the world of buying, selling and advertising from 1935 to 1965 at a pivotal point in American production, consumption, and media/technology. The collection provides access to thousands of market research reports by pioneering analyst Ernest Dichter who founded the Institute for Motivational Research (1946). In contrast to other advertising experts and market analysts post World War II, “Dichter’s techniques were largely qualitative, focusing on depth interviews and projective tests rather than simple surveys” (“Nature and Scope”). Types of sources included American Consumer Culture are either graphic still images or text and include: memoranda, reports, advertisements, and other industry or business-related documents. Advanced searches have Boolean, primary/secondary source, and (corporate) brand filters.
The search process and metadata mining is quite impressive allowing the user to ask and answer questions based on a variety of searchable fields including author, date, document type, keyword, These fields are also cross-referenced chronologically and thematically with additional components of the database: a comprehensive timeline and thirty-one thematic collections organized within the larger structural framwork (ex. retail and wholesale). Each thematic collection includes an introduction, description, and examples. (See: Industries). There are a few cracks in their metadata search engine, for example, it is difficult to determine where and how many of these documents were used. The use and audience of advertisements is quite simple, but for the many documents (reports, studies, memos), one wonders: Who was the audience and how did that affect and shape the conclusions drawn and arguments presented.
Within the record of the digital object, American Consumer Culture: Market Research and American Business continues to impress. Here is an example for a document entitled “The A-B-C of humor in advertising” — a 1967 report published by Leo Burnett Company, Inc. Click on the image to enlarge.
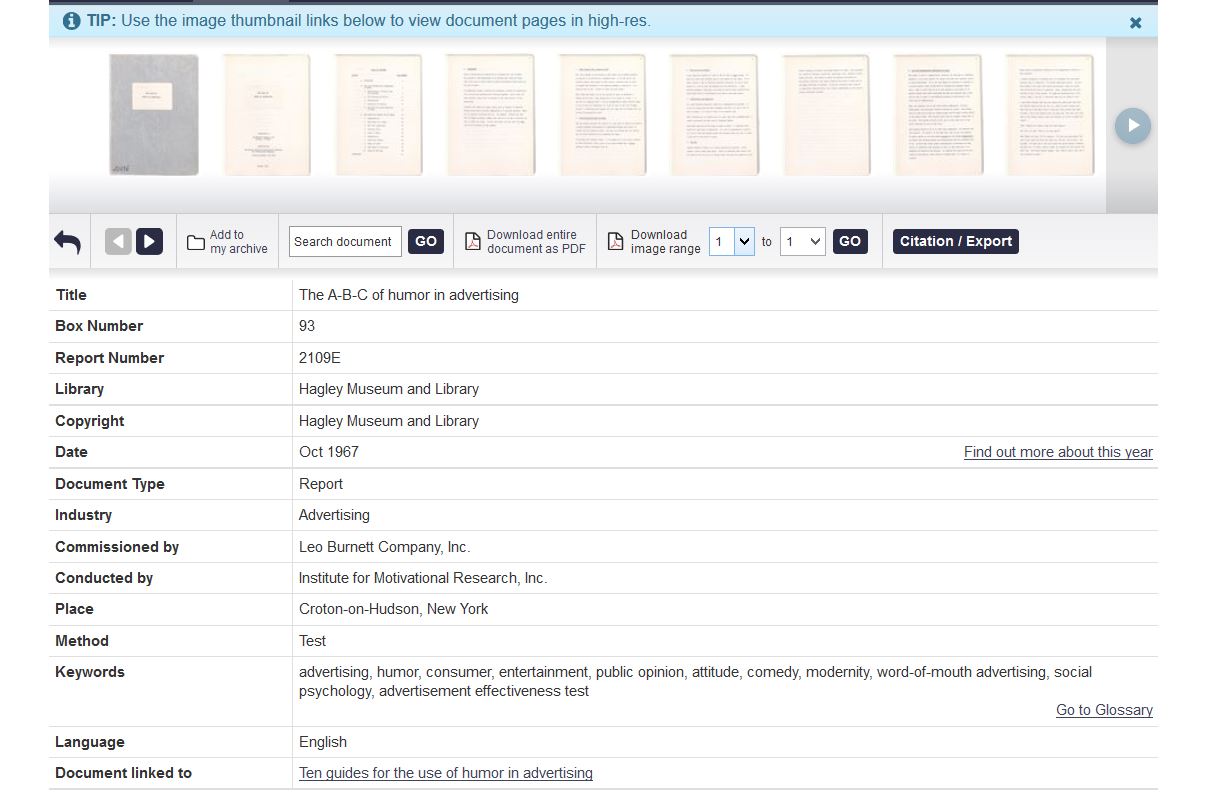
This search result, and the metadata included, is a great model for creating clear and consistent “data about data.” It describes several of the documents features including physical location of the original (box #, report #), holding library or institution, language, related document info link, date, and copyright. In terms of the original document, additional information is provided: document type, industry, commissioned by (original producer), conducted by (consulting firm), location of consulting firm, method of consultation (ex. test, survey), and keywords. All of these categories work with controlled vocabulary–a key component in creating “successful” metadata. There are also links to their controlled vocabulary glossary and a link to relevant chronology.
As for the features of the digital objects described by metadata, there are options to download as PDF, pages can be viewed in full page or thumbnail view. The document is also keyword searchable and offers an export/citation option. Features not describe by metadata are the scanning specification, scan technician, application, pixels, dpi, and other metadata related to the actual digitization process. Some of this information can be attained by right-clicking the “properties” of the document once downloaded but are not available from the database itself.
American Consumer Culture is a great example of the overlap between definitions that both compete and complement (and heavily discussed in our readings): project, collection, database, and digital thematic research. In the end, regardless of categorization, American Consumer Culture epitomizes “the closest thing that we have in the humanities to a laboratory,” as Kenneth Price argued.
*Copyright information listed on the use of images or text accessed through American Consumer Culture: This selection of images is protected by copyright, and duplication or sale of all or part of the image selection is not permitted, except that the images may be duplicated by you for your own research or other approved purpose either as prints or by downloading. Such prints or downloaded records may not be offered, whether for sale or otherwise, to anyone who is not a member of staff of the publisher. You are not permitted to alter in any way downloaded records without prior permission from the copyright owner. Such permission shall not be unreasonably withheld.