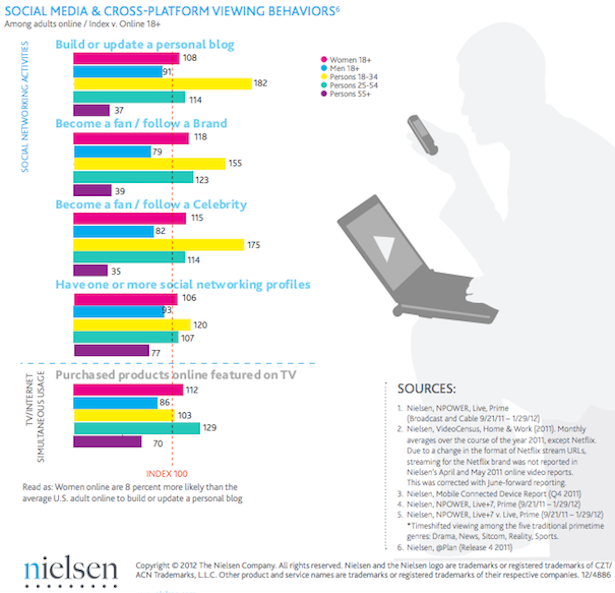
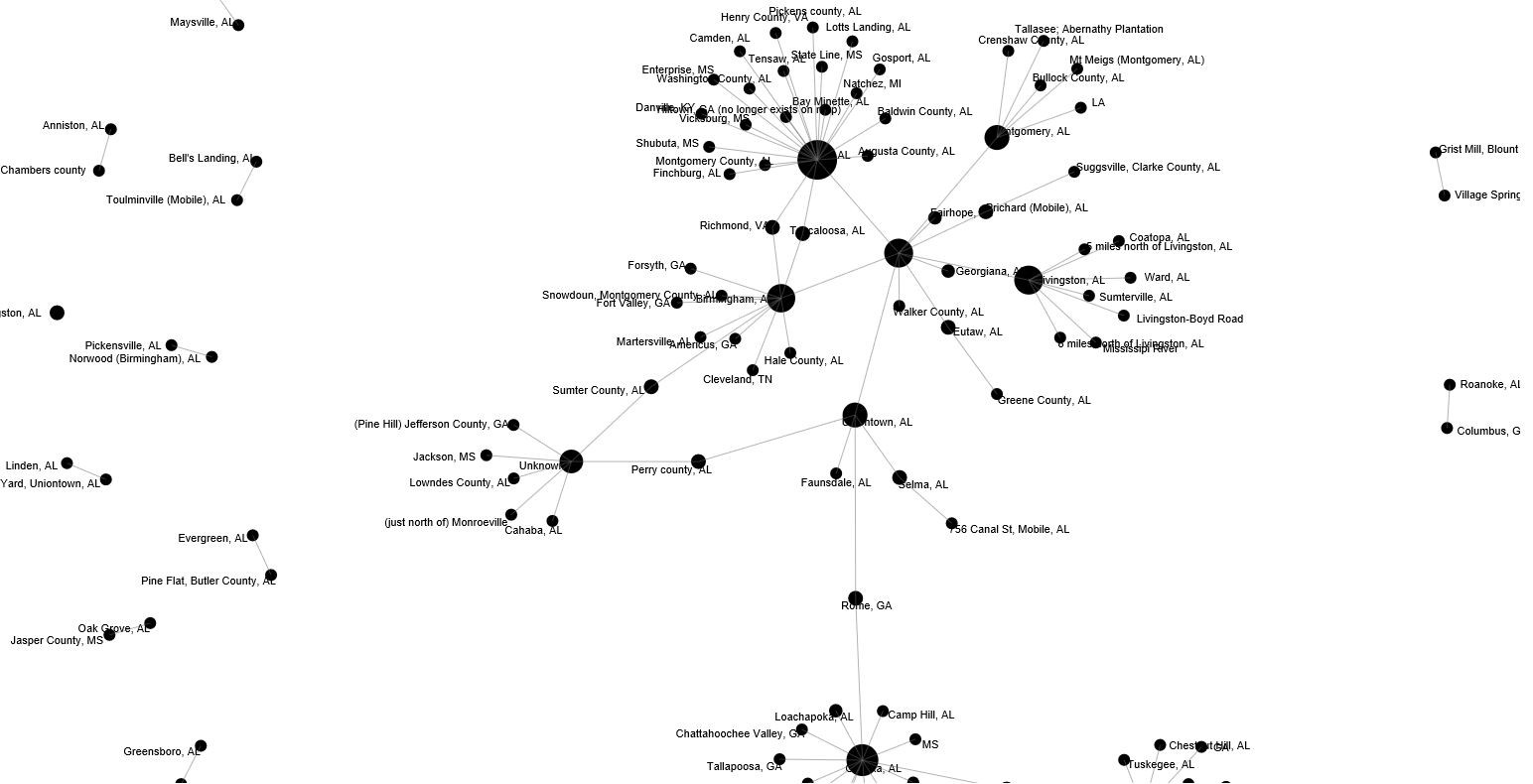
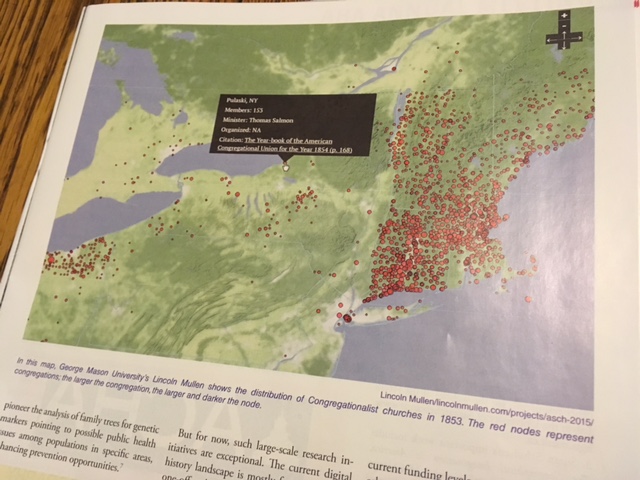
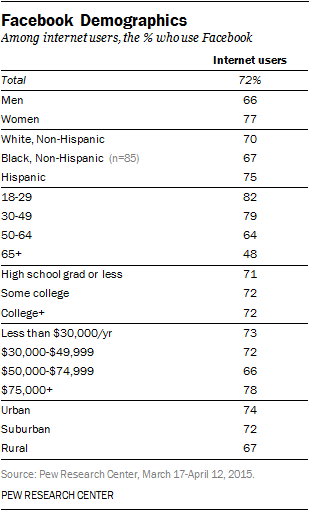Ron Grele poses three important questions in “Whose Public? Whose History? What is the Goal of Public History?” While this article, written in 1981, does not address the digital methods that have changed the look, feel, and reach of Public History–it is worth noting that the basic purpose and audiences have remained the same.
The question of “Whose Public?” aims at defining audience. I believe my role as an archivist and author is connected to several audiences: those engaged in the southern history, urban development, and higher education; undergraduate students at Belmont; student and alumni at Harpeth Hall; and local historians and preservationists. The digital element connected to Public History is now more important than ever.
The question of “Whose History?” addresses interpretation, intended audience, and sponsoring institution. For example, in Nashville, an exhibit curated by the non-profit Country Music Hall of Fame will be very different from a “War Memorial Auditorium” exhibit curated by the Tennessee State Library and Museum (state govt). And an a new exhibit installed at Ryman Auditorium, part of the for-profit company Gaylord Entertainment, provides even greater contrast with the first two examples. All three share common elements such as bolstering the historic image of Nashville, showcasing the city’s music industry, and celebrating the important role of the Grand Ole Opry. But to answer “Whose History?” and how that history is portrayed is clouded by an institutions dependence on tax dollars (or tax exemptions), the ability (or legality) to fundraise, and how the cost-benefit value is measured (i.e. profit, attendance, school groups, etc.). In an article entitled “A Picture of Public History,” published by the AHA in 2009, a survey reflects the wide-ranging nature of the field:
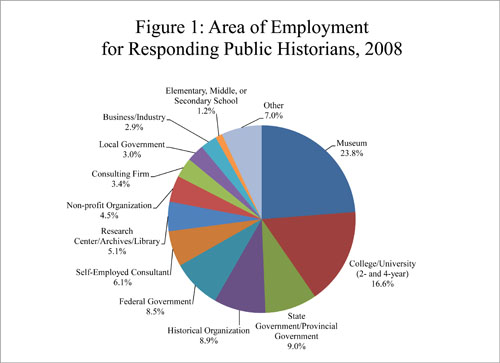
To answer the question of “What is the Goal of Public History?” is a broad question, one that has caused more disagreement than agreement within academia. John Dichtl and Robert B. Townsend surveyed nearly 3,000 professionals in history-related fields. One respondent commented, “A historian is a historian whether working in government, academia, or private industry.” Denise Meringolo suggests that public historians are a unique breed, perhaps the “little sister” of academic history with a different set of tools and intended outcomes. For me, the goal of Public History remains three-fold: to engage, educate, and disseminate history to the general public, to students and colleagues, and to the local community. Despite differences of opinion in regard to the scope and purpose of Public History (in our module readings), this simplistic statement drives my basic understanding of the field which, in turn, fuels my interest in Digital Public History.
Sources:
John Dichtl and Robert B. Townsen, “A Picture of Public History: Preliminary Results from the 2008 Survey of Public History Professionals,” Perspectives in American History (September 2009). The article is available online at https://www.historians.org/publications-and-directories/perspectives-on-history/september-2009/a-picture-of-public-history.
Lawrence B. de Graaf et al, Survey of the Historical Profession: Public Historians, 1980–81 (Washington, D.C.: American Historical Association, 1981). The report is available online at http://www.historians.org/info/SurveyofProfession_Public_80_81.pdf.
Ronald Grele “Whose Public? Whose History? What is the Goal of Public History?” The Public Historian 3.1 (Winter 1981): 40-48.
Denise D. Meringolo, Museums, Monuments, and National Parks: Toward a New Genealogy of Public History (Amherst: University of Massachusetts Press, 2012).