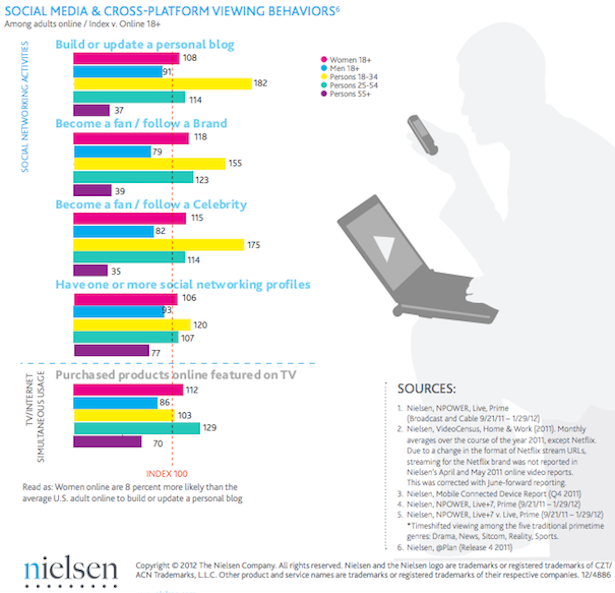
Social media is not just persuasive, it is pervasive in today’s world of constant online information, updates, and announcements. Moreover, growing numbers (particularly in the 18-34 demographic) get their news and information solely from mobile devices and many via social media platforms such as Facebook, Twitter, and Instagram. Social media is also useful because it is free, unlike television or print advertising.
The nature of my digital history final project is one that specifically targets a college-age demographic but also should (I hope) appeal to a larger audience interested in Nashville history, life, and culture. Thus my audience is three-fold: college students, scholars who specialize in southern history or urban studies, and residents of Davidson County.
My strategy aims to reach each of these groups through overlapping information using two social media platforms: Twitter and Facebook. Twitter will be used to generate interest, pose questions, and highlight parts of the digitized collection to drive internet traffic to my Omeka exhibit and related issues to Nashville’s in the news. Over 35% of all college students use Twitter, and in fact, I have already used it in classes that I teach. Facebook will be used to convey the same information but in greater detail. In addition to a greater range of features, Facebook’s audience also spans a wider spectrum as evidenced by the chart below (source: Pew Center, 2015).
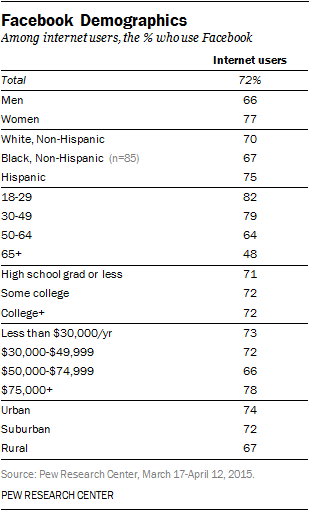
There are specific and broad messages that will be conveyed to my three audiences via Twitter and Facebook. New additions to the collection, new exhibits, and student work can be announced and introduced via Twitter and Facebook. Any events connected to the collection such as a Semester Showcase of student projects connected to the the study of Nashville can also be promoted. It is my hope that as this project develops and work is uploaded (born digital), social media can be used enhance the historical value of the work and attract “followers” who might also have contributions to make. At this time, there are no specific actions that I want potential audiences to take other than to observe and learn from the unique studies presented by my students as they investigate Nashville’s public transportation system, present original research, and explore the city’s downtown landmarks. I suppose that the digital project could inspire audiences (outside of class) to follow the designed walking tour of downtown for themselves.
My strategy of using Twitter and Facebook can be measured by the using the SMART strategy rubric:

- Specific (Who?):
Participants (students) and audiences (college students, faculty, and those interested in Nashville history) - Measurable (What?)
To monitor project site visits through stat tracker and base social media posts via interest shown
- Attainable (How?)
To post to Facebook twice per month, and Twitter weekly - Realistic (How, Why important?)
Posting once per month via FB and Twitter weekly is realistic and will keep the digital project relevant. Student in current courses can also help to promote the site by tagging or liking my posts.
- Time-bound (When?)
Over the next academic year (at a minimum)